[AINews] Llama 3.1: The Synthetic Data Model • ButtondownTwitterTwitter
Chapters
AI News: Llama 3.1 - The Synthetic Data Model
AI Reddit Recap
AI Discord Recap
Llama Discord Communities Updates
PC Setups and GPU Discussions
Automate Speaker Diarization and Transcriptions
HuggingFace ▷ #interesting-links
Nous Research AI ▷ reasoning-tasks-master-list
User Discussions on LM Studio Performance and Capabilities
OpenRouter General Discussions
CUDA Mode Beginner
OpenAI Discussions on API and Prompt Engineering
Interconnects (Nathan Lambert) Memes
DSPy Community Conversations
LangChain AI General
Creating Scheduler Agent, LangGraph & MapReduce, Llama 3.1 Hosting
Discussions on Various AI Topics
AI News: Llama 3.1 - The Synthetic Data Model
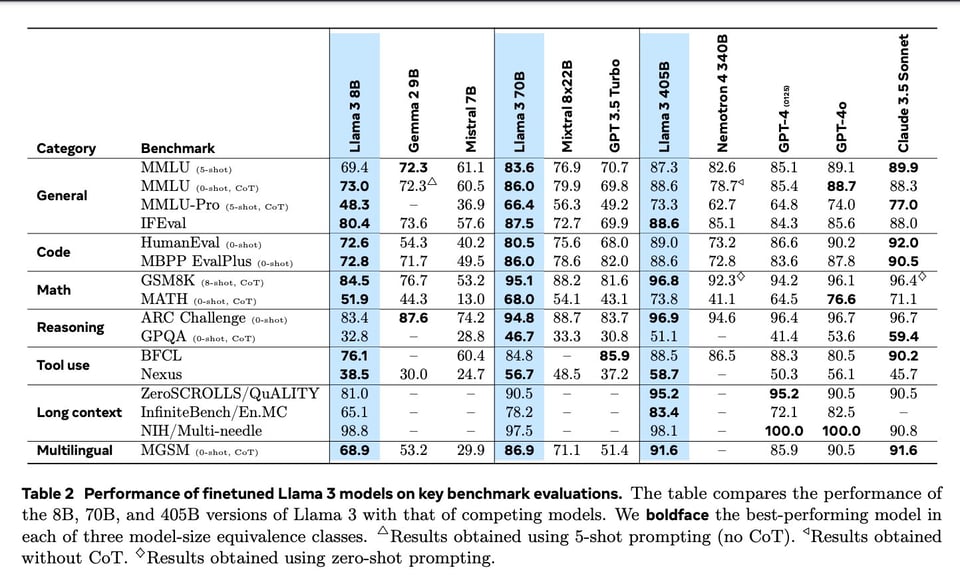
The latest edition of AI News features Llama 3.1 and its Synthetic Data Model. The post provides an overview of the key highlights, such as the extensive coverage of multiple platforms, the launch of the 405B model, and the implications of Llama 3.1 in the industry. The section also delves into the various aspects of synthetic data elements in Llama 3.1, including SFT for Code, Math, Multilinguality, Long Context, and Tool Use. Moreover, it discusses the use of DPO preference data on Llama 2 generations and the license update received by Llama 3.1. The post concludes by highlighting the introduction of a frontier-class open LLM and the advancements in cost per intelligence since March.
AI Reddit Recap
OpenAI's Universal Basic Income Experiment Results
- OpenResearch, a team at OpenAI, has released initial results from their Universal Basic Income (UBI) study. The study, conducted in Kenyan villages, found that a $1,000 cash transfer resulted in significant positive impacts, including a $400 increase in assets and a 40% reduction in the likelihood of going hungry. These findings contribute to the growing body of evidence supporting the effectiveness of direct cash transfers in alleviating poverty.
OpenAI founder Sam Altman secretly gave out $45 million to random people
- Sam Altman's $45 million UBI experiment revealed: The OpenAI founder secretly distributed $45 million to 3,000 people across two U.S. states as part of a Universal Basic Income (UBI) experiment. Participants received $1,000 per month for up to five years, with the study aiming to assess the impact of unconditional cash transfers on recipients' quality of life, time use, and financial health.
AI Researcher Predictions on AGI Timeline
- (Image linked) Several AI researchers provided their predictions on the timeline for achieving Artificial General Intelligence (AGI). The predictions varied widely, with some estimating AGI within the next decade, while others believed it could take more than 50 years. Factors influencing the timeline included technological advancements, ethical considerations, and the interdisciplinary nature of AI research.
AI Discord Recap
A summary of summaries of various AI-related discussions on different Discord channels, covering topics such as advancements in AI training infrastructure, AI surpassing human intelligence, new AI models and their performances, challenges in model fine-tuning, community debates on AI innovations, and more. These discussions touch on a wide range of subjects, including model comparisons, performance optimizations, implications of new AI technologies, and community engagement in exploring the capabilities and challenges of AI systems.
Llama Discord Communities Updates
Modular (Mojo 🔥) Discord
- Open call for presentations at the Mojo Community Meeting on August 12.
- Proposal to work on short string optimization and small buffer optimization.
- Discussion on installing Mojo within an Ubuntu VM.
- Potential for Mojo in creating next-gen game engines.
- Dialogue ongoing on improving Mojo's linking capabilities with C libraries.
Eleuther Discord
- User faced a 20x slowdown when adding nn.Parameters with FSDP.
- Member successfully hosted Llama 3.1 405B instruct on 8xH100 80GB hardware.
- Introduction of Switch SAE architecture for efficient training.
- Concerns raised over Llama 3's image encoder resolution limit.
- Recommendations for using groups and tags for task organization.
Interconnects (Nathan Lambert) Discord
- Speculation of Meta announcing a Premium version of Llama 405B.
- Concerns raised about NVIDIA potentially monopolizing the AI landscape.
- OpenAI's introduction of free fine-tuning for gpt-4o mini up to 2M tokens/day.
- Launch of the Magpie paper focusing on generating high-quality instruction data.
- Ongoing discussions about model watermarking and user download tracking with Llama 3.1.
OpenAccess AI Collective (axolotl) Discord
- Mixed reactions to the Llama 3.1 release particularly in comparison to models like Mistral.
- Users facing training challenges with Llama 3.1 and finding workarounds.
- Concerns over the exclusion of Chinese language support in Llama 3.1.
- Community discussions comparing evaluation scores of Llama 3.1 versus Qwen.
- Exploration of LLM distillation pipeline to optimize model training efficiencies.
DSPy Discord
- Introduction of Code Confluence tool for GitHub summaries inspired by DSPY.
- Sharing of a new AI research paper for analysis and discussions.
- Discussion on JSON generation libraries Jsonformer and Outlines.
- Users express challenges with Llama3 structured outputs and suggest solutions.
- Experiences shared using ColPali for RAG of medical documents with images.
LlamaIndex Discord
- Announcement of upcoming webinar on Efficient Document Retrieval with Vision Language Models.
- Details about TiDB Future App Hackathon offering $30,000 in prizes.
- Exploration of mixture-of-agents approach for enhancing model capabilities.
- Availability of Llama 3.1 models and clarification on context_window parameters.
- Introduction of efficient YouTube Notes Generator tool for note-taking.
Latent Space Discord
- Release of Llama 3.1 with 405B model and its performance evaluations.
- Commencement of the International Olympiad for Linguistics (IOL).
- Insights into Llama pricing strategy and early evaluations on performance benchmarks.
- Launch of GPT-4o Mini fine-tuning capabilities by OpenAI.
- Discussion on Llama's performance and evaluation metrics complexity.
LangChain AI Discord
- Clarification on AgentState vs InnerAgentState distinction and setting up Chroma Vector Database.
- Guide for creating a Scheduler Agent using Composio and LangChain.
- Announcement of YouTube Notes Generator launch and AI Code Reviewer Ft. Ollama & Langchain video.
- Exploration of AI applications and efficient coding practices.
- Community engagement in optimizing OCR solutions and RAG-based ChatBot systems.
Cohere Discord
- Welcome of new members to the Cohere community.
- Progress on fine-tuning with midicaps dataset and clarification on OCR solutions.
- Discussion on RAG Chatbot systems and launch of Rerank 3 Nimble with major improvements.
- Examination of innovative fine-tuning efforts and competitive pricing strategies.
- Highlights of evaluation results on Llama's performance and GPT-4o Mini fine-tuning launch.
Torchtune Discord
- Official launch of Llama 3.1 supporting 8B and 70B instruct models.
- Details about setting up Chroma Vector Database and creating a Scheduler Agent.
- Announced launch of YouTube Notes Generator and AI Code Reviewer Ft. Ollama & Langchain video.
- Community exploration of efficient code review practices and AI utilization.
- Introduction of Rerank 3 Nimble for increased speed in enterprise search.
PC Setups and GPU Discussions
Members of the HuggingFace Discord channel are actively engaged in discussions related to building PC setups and GPU preferences. Users are sharing tips, recommendations, and experiences regarding hardware components, GPU models, and overall system configurations. The community's interest in optimizing performance and selecting the best equipment for different tasks is evident, reflecting a shared passion for leveraging technology efficiently.
Automate Speaker Diarization and Transcriptions
A member is seeking a way to automate speaker diarization, whisper transcriptions, and timestamps for uploaded WAV files into a single database. They are looking for open source repositories or models to implement this pipeline.
HuggingFace ▷ #interesting-links
Bud-E Voice Assistant Gains Momentum:
A demo of the Bud-E voice assistant showcases its potential for accessibility and open-source adaptations, with the code base currently optimized for Ubuntu laptops.
- Daily hackathon meetings are hosted by Christoph to onboard new volunteers and coordinate project efforts, enabling community contributions.
Llama 3.1 Breaks Ground for Open AI Models:
The Llama 3.1 405B model is described as the largest open-source model, offering capabilities that rival top closed-source alternatives while being accessible for commercial and research use.
- Developers can leverage its functionalities for tasks such as synthetic data generation and model improvement, though operational costs are high.
Discussion on Synthetic Dataset Creation:
Concerns were raised about the costs associated with the Llama 3.1-405B for creating synthetic datasets, prompting inquiry about the viability of using the 70B model instead.
- While the 70B model is considered sufficient for many tasks, its cost-effectiveness in dataset creation remains a critical discussion point.
Microsoft's Graph RAG Proposal:
Microsoft introduced GraphRAG, a method aimed at enhancing LLMs by integrating them with private datasets for semantic understanding and clustering.
- This approach seeks to advance the capabilities of LLMs in analyzing data less familiar to them by utilizing knowledge graphs for better contextual answers.
Launch of DSPy Python Library:
A new Python library developed for integrating with DSPy optimizers claims to enhance evaluation metrics in AI applications significantly.
- The library facilitates easy integration into existing apps, allowing developers to optimize their systems effectively and encouraging community engagement on social media.
Nous Research AI ▷ reasoning-tasks-master-list
Exploring Open Reasoning Tasks Framework:
Discussion centered around improving the structure and aesthetic of the Open Reasoning Tasks repository, with suggestions for a master list format that differentiates tasks and includes examples.
- Proposals for input structures included using headlined markdown formats and tables for example outputs, balancing clarity and usability for contributors.
Incorporating Multi-modal Tasks:
Participants deliberated on how to handle multi-turn tasks and various modalities, considering whether to utilize tables for structured inputs while ensuring flexibility for contributors.
- The idea of excluding complicated tasks from table requirements while allowing contributors discretion was put forward.
Collaboration and Future Contributions:
Team members expressed intentions to contribute to the repository with updates and improvements, while confirming ongoing discussions sparked by shared papers.
- References to outside resources, particularly in Bayesian reasoning and structured problem-solving techniques, were highlighted as valuable inputs for future development.
Developing a Master List for Reasoning Papers:
The possibility of creating a comprehensive master list for reasoning-related papers and resources was discussed, with input on structuring presentation for clarity.
- Examples included potential headings and abstract formats, aiming to enhance accessibility for contributors and readers.
Utilizing SMT Solvers for Enhanced Reasoning:
A user mentioned the potential to leverage SMT solvers in translating word problems into SMTLIB formats, hinting at the creation of synthetic data for enhanced reasoning.
- This approach aligns with recent discussions on integrating logical frameworks alongside LLMs to improve accuracy in reasoning applications.
User Discussions on LM Studio Performance and Capabilities
Users engaged in various discussions related to LM Studio performance and capabilities. They discussed topics such as the performance comparison between different Llama models, issues with downloading models, GPU detection problems on Linux, capabilities of Llama 3.1, and advice on ROCm installation for AMD GPUs. These discussions provided insights into the challenges and recommendations shared among users, emphasizing the importance of hardware compatibility and model optimization for efficient usage of LM Studio.
OpenRouter General Discussions
The discussion in the OpenRouter general channel focuses on various topics related to AI models and features. Users talk about the strong capabilities of the new Llama 405B model, noting its impressive reasoning abilities in English but some limitations in foreign languages compared to other models. There are discussions on obtaining custom API keys from different providers and how to effectively utilize them. Participants also compare Llama 3 with Llama 3.1, highlighting the enhancements in the 3.1 version distilled from the larger 405B model, offering improved context length limits.
CUDA Mode Beginner
CUDA Mode Beginner
- ncu Output Interpretation: A member inquired about the speed or time taken for a CUDA kernel using
ncu ./kerneland noted durations for normal and tiled matrix multiplications. They expressed confusion about the performance improvement from tiling not aligning with textbook expectations. - Limited Improvement from Tiling: Another member shared that transitioning from naive to tiled matrix multiplication didn't yield significant speed improvements, similar to findings in an article. They highlighted that significant speedups are typically observed only with thread tiling.
- Importance of Compute Intensity: A member emphasized increasing compute intensity for better performance, specifically to escape the left side of the roofline model. This strategy was seen as crucial at the initial stages of optimizing CUDA kernels.
OpenAI Discussions on API and Prompt Engineering
OpenAI ▷ #prompt-engineering (7 messages):
-
Meta-Prompting Revolutionizes Prompt Engineering: Meta-prompting is highlighted as a top method for mastering prompt engineering, enabling users to create prompts that generate further prompts. With this technique, users can significantly enhance their ability to craft effective prompts based on AI guidance.
-
Concerns Over Plagiarism in Output: One member expresses frustration that using a blog results in 100% plagiarism in content generated by prompts. Solutions or ideas to mitigate this issue are sought.
-
Seeking Solutions for Prompt Improvement: In response to concerns about plagiarism, a member suggests sharing prompts and custom instructions to gain insights and suggestions from others. Transparency and collaboration are encouraged for prompt enhancement.
OpenAI ▷ #api-discussions (7 messages):
-
Learn to Prompt with Meta-Prompting: Meta-prompting is recognized as a top method for mastering prompt engineering, allowing users to create prompts that generate further prompts. This technique can significantly enhance one's ability to craft effective prompts based on AI guidance.
-
Concerns about Plagiarism from Blog Content: A user raises concerns that utilizing a blog results in 100% plagiarism in every generated prompt. Discussions focus on improving the originality of generated content.
-
Suggestions for Better Prompting: A member suggests sharing specific details from previous prompts and the context to receive more tailored advice. The importance of articulating desired differences in response quality is highlighted for effective prompting.
Interconnects (Nathan Lambert) Memes
OpenAI's Unexpected Refund: OpenAI accepted defeat against Llama 3.1 and randomly refunded a user an unexpected amount. They expressed gratitude with a simple acknowledgment.
Managing ChatGPT Memory Like a Game: Memory management for ChatGPT was compared to inventory management in a game, with users quitting when Memory becomes full.
Inside Mark Zuckerberg's AI Era: A YouTube video titled 'Inside Mark Zuckerberg's AI Era' was shared to discuss the ongoing battle in the AI landscape, emphasizing Meta CEO Mark Zuckerberg's position in the competition between open and closed models in AI.
Snail Enthusiasm Shared: A user shared an image of a snail in motion, sparking a positive response and a shared newfound love for snails in the community.
DSPy Community Conversations
Exploring LLM Distillation Pipeline: Discussion on the implementation details of distillation pipeline for LLM.
ColPali's Innovative Approach to Document Retrieval: ColPali's method of directly embedding page screenshots with VLMs for improved retrieval performance.
Comparison of JSON Generation Libraries: Evaluation of JSON generation libraries like Jsonformer, Outlines, and Guidance.
Interest in DSPy Optimizer Updates: Questions raised about plans to merge backend refactor of DSPy and experimenting with new optimizers.
Seeking LLM for Tense and Perspective Adjustment: Inquiry about LLM or script using Spacy to change verb tense and perspective of text.
LangChain AI General
A question was raised about the difference between AgentState and InnerAgentState in LangChain. While the definition for AgentState was clarified, there is insufficient information regarding InnerAgentState, suggesting users check the official LangChain documentation. Details regarding AgentState include fields like messages, next, and others depending on context, with references provided for further exploration. Instructions were provided on how to set up Chroma as a vector database using Python, including installing langchain-chroma and running the Chroma server in a Docker container. Examples included using methods like .add, .get, and .similarity_search, emphasizing the need for OpenAI API Key to utilize OpenAIEmbeddings. A query was made about creating a multi-character improv chatbot using LangChain. While explicit support wasn't confirmed, it was mentioned that LangChain offers features like streaming and message history management which could enable such functionality. Helpful resources from LangChain documentation were shared, including tutorials on Conversational RAG, Agents, and message history management.
Creating Scheduler Agent, LangGraph & MapReduce, Llama 3.1 Hosting
Three important topics were discussed in this section: creating a Scheduler Agent using Composio, LangGraph and MapReduce for parallel processing, and the availability of hosting for Llama 3.1.### Create a Scheduler Agent using Composio: A guide was shared on creating a Scheduler Agent with Composio, LangChain, and ChatGPT for event scheduling based on received emails. The guide emphasizes how Composio equips agents with tools to handle complex tasks effectively.### LangGraph and MapReduce for Parallel Processing: A post explores how LangGraph and MapReduce work together for parallel processing tasks in big data. The key is breaking down tasks for parallel execution, improving complex computations.### Llama 3.1 Hosting Available: A member announced hosting of Llama 3.1 405B model and invited others to try it out. This hosting offers a user-friendly environment for members to interact with the latest model version.
Discussions on Various AI Topics
This section covers discussions on various AI topics within different channels, including Int8 usage, ComfyUI flow, Llama 3.1 release, Whisper Speech Tool, and Zuckerberg discussing Llama 3.1. Members engaged in queries, updates, and sharing of information, showcasing a dynamic and active community interested in AI advancements and models.
FAQ
Q: What are the key highlights of Llama 3.1 and its Synthetic Data Model?
A: The key highlights of Llama 3.1 include extensive platform coverage, the launch of the 405B model, and its implications in the industry. It also features synthetic data elements like SFT for Code, Math, Multilinguality, Long Context, and Tool Use.
Q: What were the results of OpenAI's Universal Basic Income (UBI) experiment in Kenyan villages?
A: The $1,000 cash transfer in the UBI study resulted in significant positive impacts, including a $400 increase in assets and a 40% reduction in the likelihood of going hungry.
Q: What was the aim of Sam Altman's $45 million UBI experiment?
A: Sam Altman's UBI experiment aimed to assess the impact of unconditional cash transfers on recipients' quality of life, time use, and financial health, by distributing $1,000 per month to 3,000 people across two U.S. states.
Q: What were the predictions of AI researchers regarding the timeline for achieving Artificial General Intelligence (AGI)?
A: AI researchers provided varied predictions on the AGI timeline, ranging from within the next decade to over 50 years, influenced by technological advancements, ethical considerations, and the interdisciplinary nature of AI research.
Q: What were the discussions in the various Discords related to AI innovations and challenges?
A: Discussions in different Discord channels covered topics such as AI training infrastructure advancements, AI surpassing human intelligence, new AI model performances, model fine-tuning challenges, community debates on AI innovations, and more.
Q: What is the significance of the Llama 3.1 405B model in the AI industry?
A: The Llama 3.1 405B model is described as the largest open-source model, offering capabilities comparable to closed-source alternatives. It can be used for tasks like synthetic data generation and model enhancement, though operational costs are high.
Q: What is the Microsoft Graph RAG proposal and its goal?
A: Microsoft's GraphRAG aims to enhance Large Language Models (LLMs) by integrating them with private datasets for semantic understanding and clustering, utilizing knowledge graphs to improve the models' ability to analyze unfamiliar data.
Q: What was the launch of the DSPy Python library focused on?
A: The DSPy Python library aims to integrate with DSPy optimizers to significantly enhance evaluation metrics in AI applications, providing an easy way to optimize systems and encouraging community engagement.
Q: What were the discussions around the development of a Master List for reasoning papers?
A: Discussions revolved around creating a comprehensive master list for reasoning-related papers and resources, with suggestions on presenting the content for clarity and accessibility to contribute to the repository's improvement.
Q: What were the insights gained from discussions on LM Studio performance and capabilities?
A: Discussions on LM Studio performance highlighted challenges such as model downloading issues, GPU compatibility problems on Linux, capabilities of different Llama models, and advice on ROCm installation for AMD GPUs, emphasizing the importance of hardware compatibility and model optimization.
Q: What were the main points discussed in the OpenRouter general channel regarding AI models and features?
A: Discussions in the OpenRouter channel focused on topics like the capabilities of the Llama 405B model, its reasoning abilities in English compared to foreign languages, obtaining custom API keys, and the enhancements in Llama 3.1 version distilled from the larger 405B model.
Q: What was the main aim of the CUDA Mode Beginner discussions?
A: The CUDA Mode Beginner discussions aimed to clarify aspects like ncu output interpretation, the importance of compute intensity for better performance, and the limited improvement seen in transitioning from naive to tiled matrix multiplication, highlighting the significance of thread tiling.
Q: What were the key points discussed in the OpenAI #prompt-engineering channel?
A: The discussions in the #prompt-engineering channel focused on meta-prompting revolutionizing prompt engineering, concerns over plagiarism in output generated from blogs, and seeking solutions for prompt improvement through collaboration and transparency.
Q: What was the unexpected refund situation in the OpenAI discussions about?
A: OpenAI accepted defeat against Llama 3.1 and randomly refunded a user an unexpected amount, sparking gratitude, illustrating mem bers likening chatGPT memory management to a game's inventory, and sharing enthusiasm for a snail image in a positive community response.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!