[AINews] Mixture of Depths: Dynamically allocating compute in transformer-based language models • ButtondownTwitterTwitter
Chapters
AI Reddit, Twitter, and Discord Recap
Modular Mojo Discord
OpenInterpreter Discord
Stability in Artificial Intelligence
AI and Custom Models Discussions
Innovative AI Model Discussions
RAG Dataset Discussion
Exploring Discussions on Modular LLMs and MoE Specialization
Discussion on Python Interop and Iterator Handling in Mojo
Phorm AI Code Search & Phorm Chatbot Engagement
HuggingFace Discord Discussions
Interconnects on Various Topics
Dynamic FLOPs Allocation in Transformers
Cohort Discussion on Various Tools and Algorithms
Top-k Routing Mechanism
AI Reddit, Twitter, and Discord Recap
This section provides recaps from various platforms such as Reddit, Twitter, and Discord, covering advancements in AI research and development, AI models and architectures, discussions, techniques and frameworks, datasets, compute infrastructure, as well as memes and humor. The recaps include discussions on topics like concerns about LLM hype, improving transformer efficiency, enhancing algorithmic reasoning, on-device models, various AI products and services updates, hardware performance, benchmarks, commoditization of language models, and more. Twitter recaps feature updates on models like Alibaba's Qwen1.5 Models, Apple's MM1 Multimodal LLM Pre-training, Google's Training LLMs over Neurally Compressed Text, and techniques like ReFT and AutoRAG. Discord recap highlights advancements such as Cohere's Command R+ LLM, live tool use in Anthropic's Claude, and a new 4-bit quantization scheme called QuaRot.
Modular Mojo Discord
Boosting Mojo's Debugging Capabilities: Engineers queried about debugging support for editors like neovim, incorporating the Language Server Protocol (LSP) for enhanced problem-solving.
Dynamic Discussions on Variant Types: The use of Variant type was endorsed over isinstance function in Mojo, highlighting its dynamic data storage abilities and type checks using isa and get/take methods as shown in the Mojo documentation.
Basalt Lights Up ML Framework Torch: The newly minted Machine Learning framework Basalt is making headlines, differentiated as 'Deep Learning' and comparable to PyTorch, with its foundational version v.0.1.0 on GitHub and related article.
OpenInterpreter Discord
An innovative wrapper for voice interactions with OpenInterpreter has been developed, triggering engagement in setup and compatibility challenges. A mysterious Compare endpoint in the OpenAI API's playground sparks intrigue. Challenges with Python 3.11+ in OpenInterpreter's 01OS lead to suggestions for stability. Issues with audio connection in 01 prompt potential bugs. Conda environments recommended for resolving TTS package installations.
Stability in Artificial Intelligence
The Skunkworks AI Discord channel discussed the Mixture-of-Depths (MoD) method for language models, enabling dynamic compute allocation similar to MoE transformers and emphasizing efficient processing. Discussions included the efficiency of AI models, advancements in grounding capabilities showcased by CohereForAI's new demo, potential future model licensing developments, and cautionary notes regarding possible malware in AI tools. Conversations in the Stability.ai Discord channel focused on the anticipation and access concerns of Stable Diffusion 3, artistic integration with AI, and technical discussions on model resource requirements and usage optimization. Noteworthy is the announcement by OpenAI on boosting developer control with enhancements to the fine-tuning API and expanded custom models program.
AI and Custom Models Discussions
In this section, users engage in lively discussions about a variety of topics related to AI and the development of custom models with OpenAI. They delve into debates on AI cognition, business ideas, the integration of AI in different fields, concerns about AI product releases, and queries about implementing AI features. Additionally, users explore issues with AI models like GPT-4 and discuss ways to fine-tune and optimize their performance. The section also highlights topics such as text embeddings, model compatibility, multi-GPU setups, and the potential of different hardware configurations in LM Studio. Furthermore, users share new model releases, troubleshooting experiences with autogen systems, and emerging solutions to enhance the functionality of AI models.
Innovative AI Model Discussions
LM Studio
-
AMD GPU Compatibility Queries: Users discussed compatibility issues with ROCm on AMD GPUs, especially the 6700XT (gfx 1031). One user reported an inability to load models despite trying various configurations, while another suggested it may be a driver issue that AMD needs to address.
-
ROCm Performance Insights: A significant performance boost was reported when using ROCm over OpenCL; one user noted an increase from 12T/s to 33T/s in generation tasks, underscoring criticisms of AMD's OpenCL implementation.
-
Linux vs. Windows Support for ROCm: ROCm has functionality limitations on Windows that don't exist on Linux, where users can spoof chip versions to get certain GPUs to work. There were hints that if ROCm for Linux is released, more graphics cards could be supported by LM Studio.
-
Anticipation for Open Source ROCm: A tweet from @amdradeon was shared about ROCm going open source, raising hopes for easier Linux build support on more AMD graphics cards. The introduction of open-source ROCm could potentially expand compatibility (Radeon's Tweet).
-
User Explorations and Configurations: Different set-ups were discussed and compared, with mentions of disabling iGPUs to run VRAM at the correct amount and varied configurations involving dual GPUs and high-performance builds for gaming transitioning towards AI and machine learning workloads.
Nous Research AI
-
LoRA Layer on Mistral 7B in the Works: A member suggested the potential of creating a LoRA (Low-Rank Adaptation) on top of models like Mistral 7B to significantly enhance its capabilities.
-
Advanced Task for AI Involves Taxonomy: In response to the LoRA suggestion, it was revealed that there are plans to not just split sentences but also to categorize each one according to a specific taxonomy for the task at hand.
RAG Dataset Discussion
Pin-worthy Planning Summaries
There is a consensus on pinning summaries for newcomers. A document containing objectives and requirements has been created, updating has begun, but it is not yet widely scoped due to contributor availability.
Adopting Adaptive RAG
The Adaptive-RAG approach, combining query analysis and iterative answer construction, has been implemented using LangGraph and Cohere's Command-R and Command R+ models. This implementation showcases the differences between using LangGraph and ReAct agents, alongside the benefits and trade-offs of using Command-R versus Command R+.
RAG and UX Innovations
Members discussed practical applications and successes with RAG, particularly in source code retrieval and post-retrieval filtering. A proposed UI concept involves keeping a vector database of entities and artifacts to streamline the user interaction process.
Exploring Retrieval Data Sources for RAG
Suggestions for sourcing retrieval data include starting with Wikipedia indices, integrating code for practical applications, considering synthetic textbooks, and adding domain-specific datasets like the Caselaw Access Project. Diversity in data sources is emphasized as ideal.
Command R+ and Claude Opus Updates
Discussions around Command R+'s instructions format were shared, and it was noted that Claude Opus performs well on complex queries. The significance of proper prompting and citing sources was highlighted, referencing cohere's platform and documentation.
Exploring Discussions on Modular LLMs and MoE Specialization
A discussion took place regarding the implementation of Modular Large Language Models (LLMs) and Mixture of Experts (MoE) specialization. One point of discussion was whether MoE architectures inherently support model interpretability by enabling expert-specific specializations within LLMs. Various MoE routing techniques, such as Expert Choice Routing, were mentioned as potential guides for the MoE gating mechanism in a context-dependent way. Another debate revolved around the advantages of hierarchical MoE structures over flat MoEs. Technical insights were shared, including the structure of router weights and the benefits of hierarchies in improving expert selection specificity. Furthermore, detailed technical information was provided on specific architectures, such as nested MoE versus flat MoE, and hyperparameter tuning, emphasizing the importance of hyperparameter optimization for new architectural methods. Additionally, a member hinted at a potential breakthrough in the efficiency of MoE models, suggesting significant computational efficiency gains in Large Language Model training. Lastly, skepticism was expressed towards a 'Schedule-Free' Learning optimizer, raising concerns about its advertised baselines and mechanics.
Discussion on Python Interop and Iterator Handling in Mojo
The conversation in the Mojo channel touched on various topics, including discussions on Python interop advancements with methods like PyMethodDef and PyCFunction_New. The integration progress showcased on the rd4com/mojo_branch repository emphasized the need for careful planning in these efforts. Contributions to Mojo's Python interop capabilities have displayed stability with no reference counting issues. Additionally, the chat addressed a bug in range handling and welcomed new contributors to the Mojo standard library. Overall, the Mojo channel highlighted the ongoing development and community engagement in Python interop and iterator management.
Phorm AI Code Search & Phorm Chatbot Engagement
- Phorm Chatbot Engaged: Introduction of Phorm chatbot for querying data within OpenAccess-AI-Collective/axolotl project discussions.
- Chat Template Formatter 101: Inquiries about chat template formatter usage and walkthrough provided by Phorm, suggesting Hugging Face's Transformers library.
- RoPE Tuning Talk: Discussion on adjusting 'rope_theta' for Rotary Positional Embedding within Transformers, requiring clarity beyond Phorm's fetch capabilities.
- Rope Scaling Query: Discussed deprecated rope scaling parameter and its relevance.
- Inappropriate Content Alert: Noted inappropriate content promotion in chat history.
HuggingFace Discord Discussions
This section provides a glimpse into various discussions happening on HuggingFace Discord channels. Members engage in topics like AI communities for face embeddings, deploying models, exploring AI hardware options, limitations of large language models, and new AI projects and platforms. The section also covers advancements in AI models such as Visual AutoRegressive modeling, chain-of-thought prompting, and new Multi-Document Agent LlamaIndex. Additionally, discussions touch on practical aspects like GPU usage monitoring, batch size dilemmas, LR schedulers, and updating datasets on Hugging Face. Lastly, the section explores technical topics related to Tinygrad, NPUs, GPU drivers, scalability, heterogeneous acceleration, and kernel-level integration opportunities, providing insights into optimizations and future developments.
Interconnects on Various Topics
This chunk covers various discussions and announcements in the AI community. Topics include the introduction of 'Command R+' by Cohere, the debate on 'ChatGPT for Business' models, the introduction of the 'JetMoE-8B' model, OpenAI's fine-tuning service, concerns over big tech mergers, and more. Additionally, there are discussions on transformer efficiency, mixing different AI models, and the anticipation of real-world implementations. Members also discuss LangChain AI, sharing work on output parsers, troubleshooting issues with chatbots, and seeking assistance for integrating Azure credentials. In another thread, a member shares a TypeScript implementation for semantic chunking, while another thread discusses tutorials in Spanish on using DSPy. The section also covers critiques of Apple's MPS, inquiries on diffusion models and audio stemming, achievements of AI agents in Kaggle competitions, and frustrations with PyTorch on macOS.
Dynamic FLOPs Allocation in Transformers
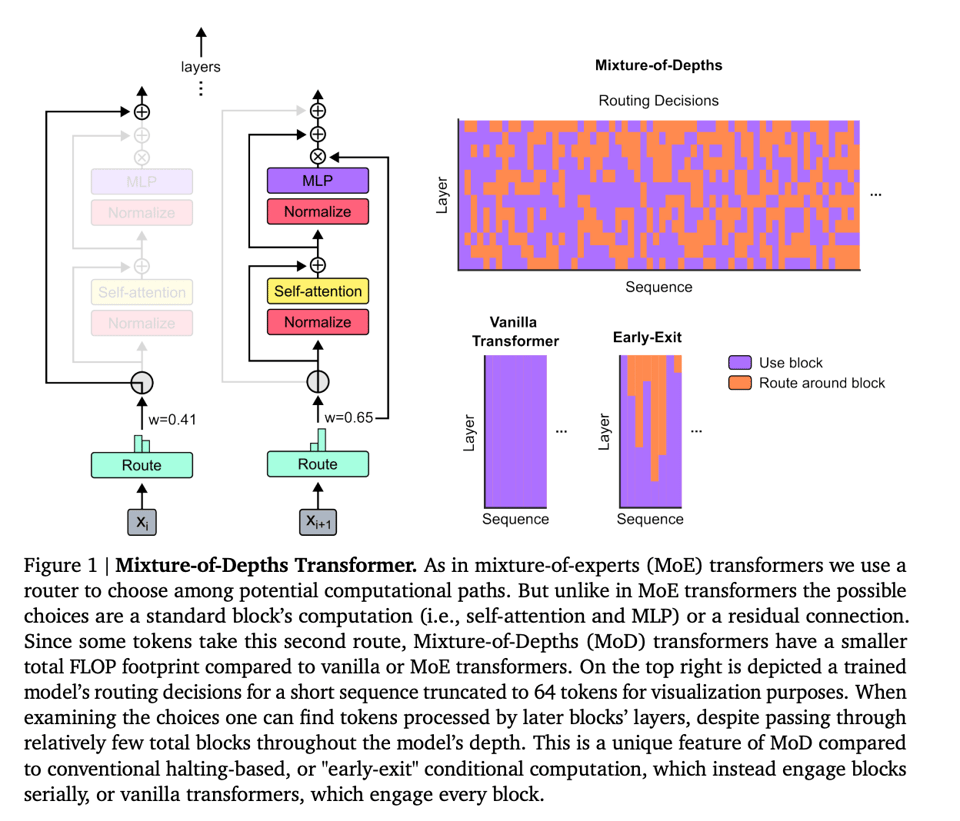
A novel approach to optimizing transformer models by dynamically allocating FLOPs across input sequences has been introduced, described in detail in the paper 'Mixture-of-Depths: Dynamically allocating compute in transformer-based language models'. The method utilizes a top-$k$ routing mechanism to limit the compute resources while still maintaining a static computation graph. Critics question the originality and practical savings of DeepMind's Mixture-of-Depths paper, while some praise the potential compute savings by reducing operations on less complex tokens.
Cohort Discussion on Various Tools and Algorithms
During this segment of the cohort discussion, several tools and algorithms were introduced and discussed among the members. Some highlights include the introduction of QuaRot, a new quantization scheme for Large Language Models (LLMs) maintaining high performance with minimal losses, and a recommendation for revisiting parallel programming classics through an Udacity course. Moreover, topics such as integrating HQQ with GPT-Fast, exploring lower bit-level quantization, lightning-fast attention with Triton, and the launch of Mozilla's AI project 'Solo' for no-code website creation were discussed. There were also detailed conversations on visual flow enhancements, operation display, benchmarking for LLMs, and model advancements by CohereForAI in the DiscoResearch channels. In another channel, the discussion focused on GPU allocation advice, utilizing Intel's oneAPI basekit, displaying tokens per second during model operation, and addressing concerns about the flagged llamafile executable. Lastly, skunkworks AI introduced the Mixture-of-Depths (MoD) method for language models, enabling dynamic compute allocation.
Top-k Routing Mechanism
The top-k routing mechanism involves adjusting processing to specific token positions as detailed in a research paper on dynamically allocating compute in transformer-based language models. The paper discusses how transformers can learn to dynamically allocate FLOPs (or compute) to specific parts of input sequences, breaking away from the traditional uniform spread of FLOPs across the entire sequence.
FAQ
Q: What are some advancements in AI research and development discussed in the provided material?
A: Advancements in AI research and development discussed in the provided material include improvements in transformer efficiency, advancements in algorithmic reasoning, discussions on on-device models, updates on various AI product and services, discussions on hardware performance and benchmarks, and advancements in AI models like Alibaba's Qwen1.5 Models, Apple's MM1 Multimodal LLM Pre-training, and Google's training LLMs over Neurally Compressed Text.
Q: What is the Mixture-of-Depths (MoD) method for language models?
A: The Mixture-of-Depths (MoD) method for language models enables dynamic compute allocation similar to Mixture of Experts (MoE) transformers by adjusting processing to specific token positions. It breaks away from the traditional uniform spread of compute resources across the entire sequence, potentially leading to computational efficiency gains in training Large Language Models.
Q: What is the top-k routing mechanism in relation to transformer models?
A: The top-k routing mechanism limits compute resources by adjusting processing to specific token positions in input sequences, maintaining a static computation graph. This mechanism aims to reduce operations on less complex tokens while still effectively allocating compute power within the transformer-based language models.
Q: What are some notable topics discussed in AI Discord channels mentioned in the text?
A: Some notable topics discussed in AI Discord channels include advancements in AI models like Visual AutoRegressive modeling, chain-of-thought prompting, and Multi-Document Agent LlamaIndex. Discussions also cover practical aspects like GPU monitoring, LR schedulers, dataset updates, and technical topics related to optimizations, NPUs, GPU drivers, and heterogeneous acceleration.
Q: What are some upcoming AI tools and algorithms discussed in the provided content?
A: Upcoming AI tools and algorithms discussed in the provided content include QuaRot, a new quantization scheme for Large Language Models with minimal performance losses; integration of HQQ with GPT-Fast; exploration of lower bit-level quantization; implementation of lightning-fast attention with Triton; and the launch of Mozilla's AI project 'Solo' for no-code website creation.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!